
在這個實作中,我們可以學到:
如昨天的Lab(Part 1 & 2),在GCP中開啟Notebooks後,複製課程 Github repo 。
在左邊的資料夾結構,點進 training-data-analyst > courses > machine_learning > deepdive > 02_generalization ,然後打開檔案 create_datasets.ipynb。
一打開後,便會看到這次lab的notebook,一開始當然是先把資料用BigQuery撈出來囉,這次的資料是紐約市的計程車費用。



decribe() 方法,可以快速地看到每行的基本統計數字如平均值、標準差、最大最小值等等。
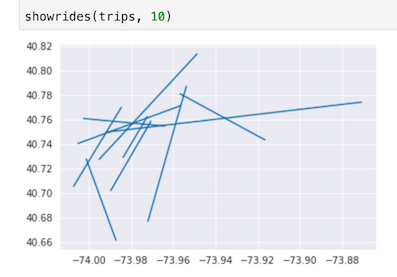
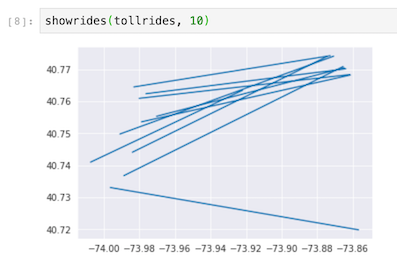
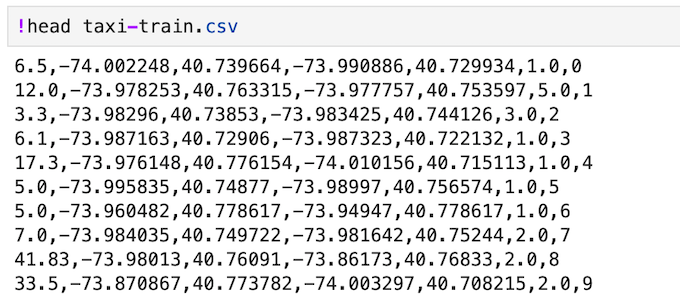


特別值得一提的是,資料的探索與前處理其實是很花時間的,尤其當你不是該資料領域的專家或是有經驗的人士(Domain knowledge在這個階段就很重要),準備良好的資料對於後續訓練是有很大的幫助的。
到這邊就是進入ML子課程的一個段落囉!接下來就是建構模型與訓練的部分,也是大家常聽到的關鍵字:TensorFlow。
今天介紹了探索和創造ML資料集,明天我們將開始第三個子課程Intro to TensorFlow。
